Computing hardware and software
The Blue Gene/Q
|


The QCDSP (top) and the QCDSP chip (bottom).
As a very large scale, homogenous problem, lattice QCD has been a driver of high performance, massively parallel computing since its inception. In fact, some of the early, highest performance parallel machines were designed and built to solve QCD. Recent examples of such machines are the QCDSP and QCDOC machines constructed by members of USQCD at Columbia University. A 600 Gflops (peak) QCDSP (QCD on Digital Signal Processors) was installed at the RIKEN BNL Research Center (RBRC) at the Brookhaven National Laboratory (BNL) (right) in 1998 and won the Gordon Bell Prize for price performance in that year. Three Ten Tflops (peak) QCDOC machines were installed at the RBRC, BNL (below left) and the University of Edinburgh in 2005. The Brookhaven machine was funded by the DOE and used by USQCD until it was decommissioned in October of 2011.


The QCDOC (top) and the QCDSP chip (bottom).
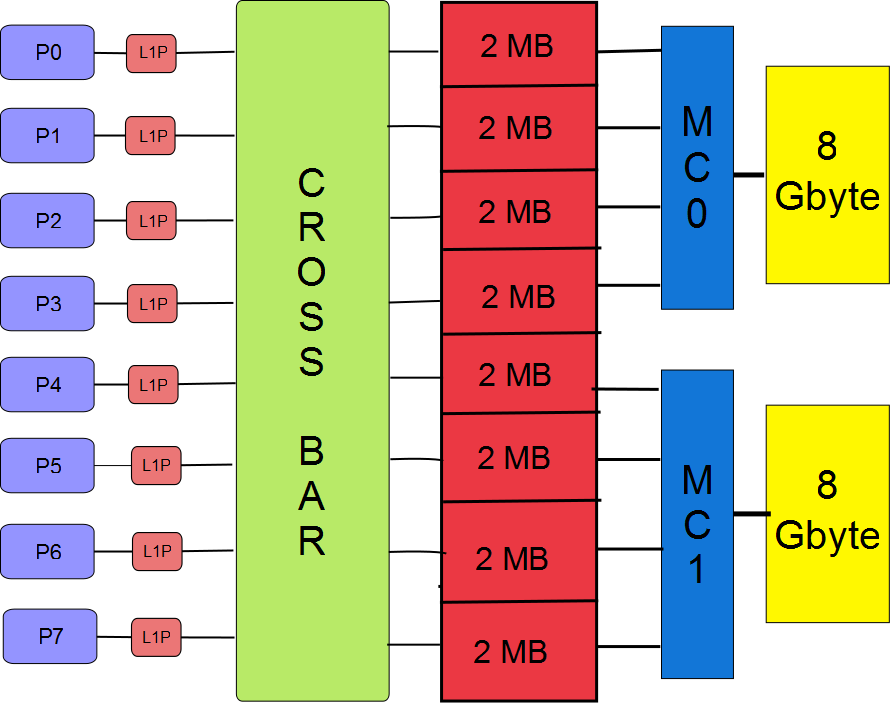
Block diagram of the Blue Gene/Q node.
The QCDSP and QCDOC machines provided inspiration for IBM's current Blue Gene series of computers. This slide from IBM, shows the roadmap which the Blue Gene designers envisioned near the start of the Blue Gene/L project. In fact the QCDOC project was carried out jointly by IBM, Columbia University, the RIKEN laboratory in Japan, BNL and the University of Edinburgh. The physicists provided the logic design and IBM provided the ASIC libraries (CPU, FPU, Ethernet controller, etc.) and the physical design and chip fabrication. The close relationship between these commercial and academic machines is well represented in the IBM Research Journal dedicated to an in depth presentation of the Blue Gene/L computer which includes an article describing QCDSP and QCDOC. [1]
When the team who built QCDOC began to plan a new project, the success of the Blue Gene machines, their high performance for lattice QCD and the strong working relation with IBM which had grown from the QCDOC project made a continued collaboration with IBM highly attractive. As a result, physicists from Columbia, Edinburgh and the RBRC became IBM contractors and joined the design team working on the Sequoia Project, now IBM's Blue Gene/Q product. The block diagram (left) shows a reduced version of the design of the Blue Gene/Q chip, depicting eight of the sixteen cores that perform computations. The small blocks labeled 'L1P' are the prefetching units for the L1 cache and were the design responsibility of the lattice QCD group. This arrangement worked well. Performing the logic and much of the physical design of this portion of the Blue Gene compute chip, required very early access to a variety of simulators and opportunities to determine and improve the efficiency of a real application at each stage of the chip design. As a result, the lowest level QCD kernel running on a single node currently achieves 65% of the theoretical peak performance of the machine.
There were also challenging opportunities to contribute innovative features to the prefetching unit. Two different prefetching engines were realized. The first is a stream prefetching unit which detects a series of L1 cache misses at a sequence of contiguous addresses. This unit uses an adaptive stream prefetching algorithm which assigns and varies a target depth for each stream prefetch buffer created within the L1p cache. By allowing these stream prefetch buffers to have varying length, the limited L1p cache is used most effectively. By varying the target depth rather than the actual buffer space, a more gentle, second-order allocation scheme is realized, reducing the eviction of needed data and resulting buffer thrashing. The second prefetching scheme is controlled by pragmas inserted in the code. For a repetitive sequence of code, this unit will memorize the resulting sequence of L1 cache misses and prefetch them `just in time' the next time this same sequence is executed. These details of the L1 prefetching hardware were recently presented at HotChips 23 [2] and are described in a recently published IEEE Micro article [3].

Early racks of the Blue Gene/Q installed at Brookhaven National Laboratory.
While designing the L1p unit there were also valuable opportunities to add features which were of direct benefit to code similar to that of lattice QCD. By providing an immediate reply to L2 cache touches, the L1p allows multiple touches to be issued without blocking the load-store queue of the A2 processor. Likewise implementing the prefetching of short, fixed length streams allows a single cache touch to prefetch an entire Dirac spinor. As a result of this early involvement BNL, the RBRC, and the University of Edinburgh have been able to take delivery of some of the first BG/Q racks. The picture shows two of these early racks which are now being brought up at Brookhaven (right).
[1] P A. Boyle, D. Chen, N. H. Christ, M. Clark, S. D. Cohen, C. Cristian, Z. Dong, A. Gara, B. Joo, C. Jung, C. Kim, L. Levkova, X. Liao, G. Liu, R. D. Mawhinney, S. Ohta, K. Petrov, T. Wettig, A. Yamaguchi, Overview of the QCDSP and QCDOC computers, IBM Research Journal, Vol 49, No. 2/3, 351 (2005).
[2] http://www.hotchips.org/archives/hc23/HC23-papers/HC23.18.1-manycore/HC23.18.121.BlueGene-IBM_BQC_HC23_20110818.pdf
[3] Ruud A. Haring, Martin Ohmacht, Thomas W. Fox, Michael K. Gschwind, Peter A. Boyle, Norman H. Christ, Changhoan Kim, David L. Satterfield, Krishnan Sugavanam, Paul W. Coteus, Philip Heidelberger, Matthias A. Blumrich, Robert W. Wisniewski, Alan Gara, George L. Chiu, The IBM Blue Gene/Q Compute Chip, Micro, IEEE Volume: PP Issue:99 page: 1, 20 December 2011.
|
|
